VLN综述
近期指导老师给我提供了研究方向——VLN(视觉语言导航),但我询问了组里的师兄之后,发现这一领域之前是没有人做过的,老师懂得也不是很多,所以需要我多花点时间和精力钻研。思来想去,还是先从综述还是看起,先把整个领域先整体浏览一遍,熟悉一下。
今天看的文章是24年12月来自密歇根州立、密歇根大学、UNC Chapel Hill 和澳大利亚阿德莱德大学的论文“Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models”,这篇文章发表在 2024 TMLR 上,这是一个较新的ML期刊。
摘要
视觉语言导航近年来获得了学界的大量关注,提出了许多新的方法。基础模型的强大能力塑造了VLN研究的挑战和方法。在本篇综述中,我们提供了一个从上到下的视角,采用原则性框架阐述具身规划和推理的发展,强调最新的方法和未来能够利用基础模型解决VLN挑战的机会。我们希望我们深入的讨论可以提供有价值的资源和观点,一方面,记录进展并探索基础模型在这个领域下的机会和可能扮演的角色,另一方面,为基础模型研究者提供VLN领域下的不同的挑战和解决方案。
前言
研发能够和人类及环境交流的具身智能体一直是人工智能发展的长期目标,这些智能体在现实世界的应用中具有巨大的潜能,例如家用机器人、自动驾驶车辆、私人助理等。推动这一方向发展的一个重要问题就是视觉语言导航(VLN),其是一个多模态和协同的任务,需要智能体遵循人类指令,探索3D环境,在各种形式的歧义下进行情境通信。最近几年,VLN已经在模拟器和真实环境下得到了探索,导致了许多benchmark的产生。
近期,基础模型(LLM,VLM)展示出了强大的多模态理解和推理能力,以及垮领域的泛化性。把他们用在VLN任务中,标志着具身智能方向的重要进展。同时,基础模型的使用也为VLN带来了新的研究方向,从原先的多模态注意力学习和战略策略学习(strategy policy learning)到预训练具有强泛化性的视觉语言表示。
本文采用LAW的框架——基础模型作为世界模型和智能体模型的骨干。该框架提供了全面的推理和规划视角,并且与VLN中的核心挑战紧密相关。
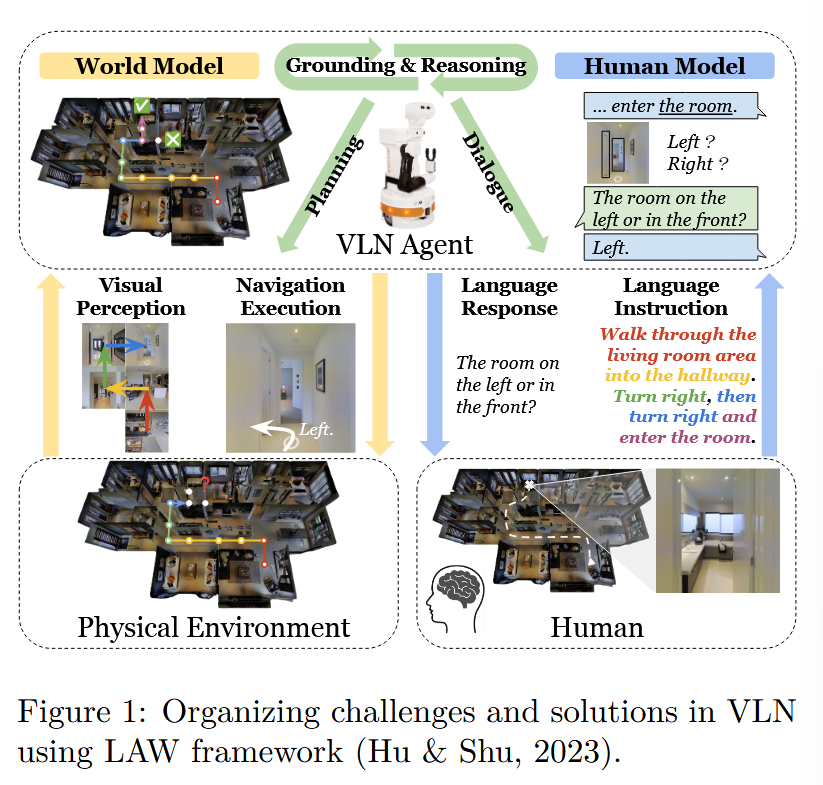
具体来说,在每一个导航步骤中,AI智能体感知视觉环境,接受来自人类的语言指示,根据他们对世界和人类的表示来决策,从而高效实现导航任务。世界模型帮助行动者理解周围的环境以及他们的行动对环境的影响,其是广义上的智能体模型的一部分,除此之外广义智能体模型还包含一个用于理解人类指令的人类模型。因此该篇综述主要围绕以下三个视角叙述根本性的挑战:
- 学习一个能够表示视觉环境,并泛化到未知环境的世界模型。
- 学习一个能够从真实指令中有效解释人类意图的人类模型。
- 学习一个能够利用世界和人类模型进行语言、沟通、推理和规划的VLN智能体,使其能够按照指示导航环境。
背景和任务形式
VLN的认知基础
人类和其他导航动物表现出对环境的早期理解和导航策略。例如Gallistel描述了两种基本机制:引导——它涉及环境地标并计算距离和角度;路径积分——通过自运动传感计算位移和方向变化。理解空间导航的核心是认知地图假说(cognitive map hypothesis),认为大脑形成统一的空间表征来支持记忆和引导导航。神经科学家发现了海马位置细胞,揭示了能够编码地标和目标的空间坐标系。最近的研究提出了非欧几里得表示。例如认知图(cognitive graphs),其解释了我们表示世界的空间知识的复杂性。VLN的研究不仅促进了在视觉环境中遵循人类指令的具身人工智能的发展,还加深了我们对认知主体如何发展导航技能、适应不同环境以及语言使用如何与视觉感知和行动相联系的理解。
相关任务和综述范围
遵循自然语言导航指令,传统上使用符号世界表征例如地图进行建模。然而,我们的综述重点关注那些利用视觉环境并解决多模态理解与语义对齐(grounding)挑战的模型。同样地,我们将读者引导至若干关于视觉导航和移动机器人导航的综述,这些研究主要聚焦于视觉感知和物理具身性。然而,这些工作对于语言在导航任务中所起的作用讨论较少。
尽管我们在讨论视觉语言导航(VLN)时不可避免地会拓展到超越导航的领域,如移动操作(mobile manipulation)和对话(dialogue),但我们的主要关注点仍然是导航任务,并对该领域的相关文献进行了详细综述。
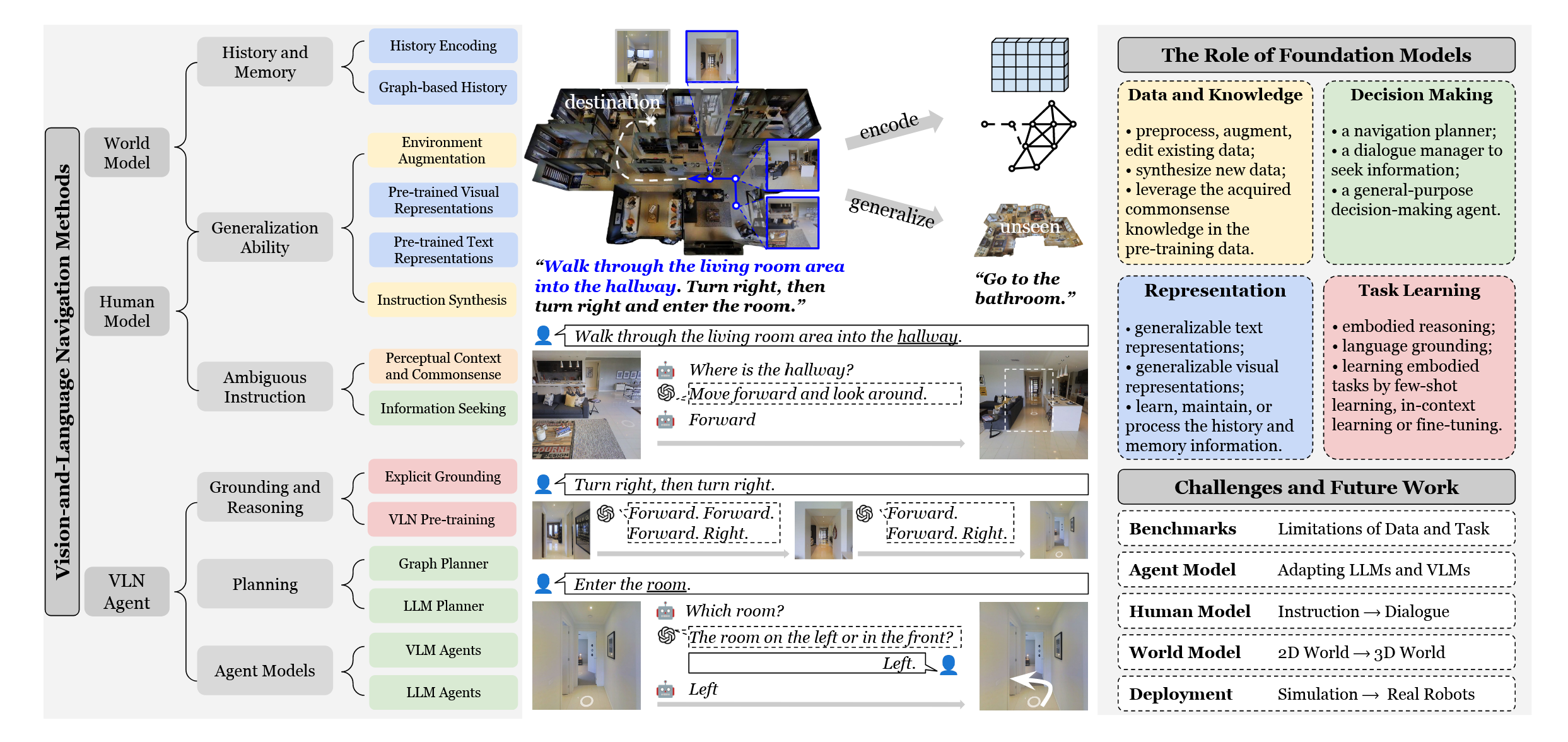
此外,与以往的 VLN 综述不同,那些研究通常采用自下而上的方式,重点总结了基准数据集与模型创新,而本综述采用自上而下的视角,根据基础模型(foundation models)所扮演的角色,将研究工作归纳为来自三个方面的三项核心挑战:世界模型(world model)、人类模型(human model)与VLN智能体(VLN agent)。
需要注意的是,本综述聚焦于与基础模型兴起相关的前沿方法。因此,对于早期一代的模型(例如基于 LSTM 的方法),我们仅在每个章节的开头作简要介绍,以引出后续的讨论。
VLN任务形式和Benchmarks
- VLN 任务定义
一个典型的视觉语言导航(VLN)智能体会在特定位置接收到来自人类指令者的一条(或一系列)语言指令。该智能体以自我视角(egocentric visual perspective)在环境中进行导航。通过遵循这些指令,它的任务是生成一条由离散视角序列或低层次动作与控制指令(例如“向前移动 0.25 米”)组成的轨迹,以抵达目标地点;如果智能体最终到达距离目标点在指定范围内(例如 3 米以内),则认为导航成功。
此外,智能体在导航过程中可能会与指令者进行信息交互,例如请求帮助或进行自由形式的语言交流。同时,近年来对于 VLN 智能体的期望也在不断提高,要求其在导航之外整合额外任务,如物体操作(manipulation)和目标检测(object detection)等。
- Benchmarks
与其他多模态任务(如视觉问答 VQA)不同,后者通常具有相对固定的任务定义与格式,而 视觉语言导航(VLN) 涵盖了多种基准与任务形式。这些差异为更广泛的 VLN 研究带来了独特挑战,因此在设计基于合适基础模型的有效方法之前,充分理解这些区别至关重要。
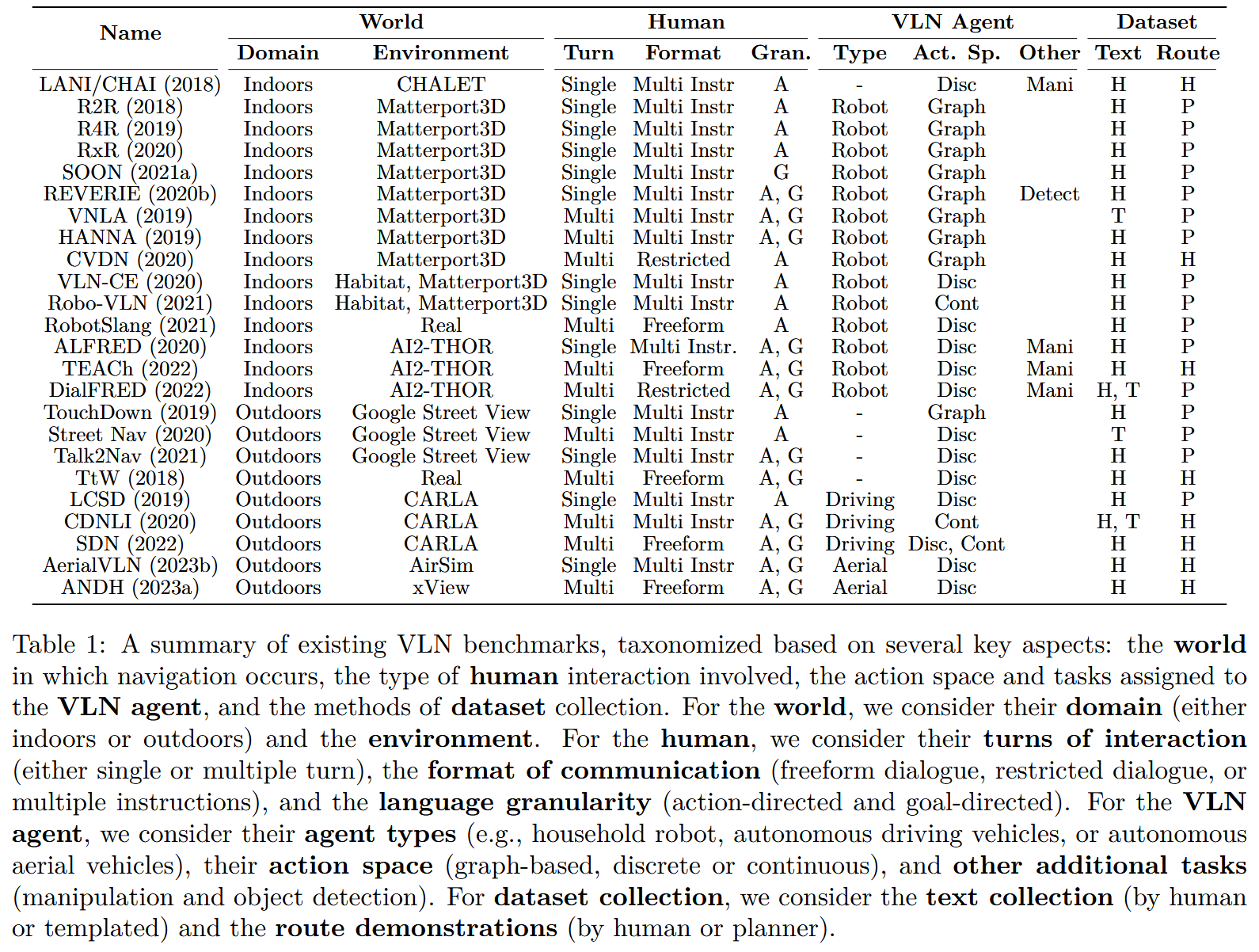
如表 1 所总结的,现有的 VLN 基准可以按照 LAW 框架(the LAW framework) 从以下几个关键方面进行分类:
- World(环境):导航发生的世界,包括领域(室内或室外)以及环境的具体特征。
- Interaction(交互):涉及的人机交互类型,包括交互轮次(单轮或多轮)、交流形式(自由对话、受限对话或多指令)以及语言粒度(面向动作的或面向目标的指令)。
- Agent(智能体):包括智能体的类型(如家用机器人、自动驾驶车辆或自主飞行器)、动作空间(基于图的、离散的或连续的)以及额外任务(如操作 manipulation 与目标检测 object detection)。
- Dataset Collection(数据集收集):包括文本的获取方式(人工生成或模板生成)以及路径演示的来源(人工演示或路径规划器生成)。
具有代表性的是,Anderson 等人(2018) 基于 Matterport3D 模拟器(Chang 等人,2018) 构建了 Room-to-Room (R2R) 数据集,在该任务中,智能体需要根据细粒度的导航指令抵达目标位置。其多语言扩展版本 Room-across-Room (RxR)(Ku 等人,2020)涵盖了英语、印地语和泰卢固语指令,具有更大的样本规模,并提供了与虚拟视点时间对齐的指令,丰富了任务的语言与空间信息。
在 Matterport3D 中,VLN 智能体在离散环境中运行,依赖预定义的连通图(connectivity graph)进行导航,智能体通过在相邻节点间“跳跃”(teleportation)移动,这种设定被称为 VLN-DE(Discrete Environment)。
为了使这种简化环境更接近现实,Krantz 等人(2020)、Li 等人(2022c) 和 Irshad 等人(2021) 提出了连续环境中的 VLN(VLN-CE, Continuous Environment),通过将离散的 R2R 路径映射到连续空间(Savva 等人,2019)来实现。进一步地,Robo-VLN(Irshad 等人,2021) 通过引入连续动作空间的设定,使得任务在机器人场景中更具现实性,从而进一步缩小了模拟到现实(sim-to-real)的差距。
近年来,VLN 基准经历了多项设计变革与期望更新,这些内容将在第 6 节中进一步讨论。
评估指标
在视觉语言导航(VLN)中,主要有三种用于评估导航寻路性能的指标(Anderson 等人,2018): (1) 导航误差(Navigation Error, NE):指智能体最终位置与目标位置之间最短路径距离的平均值; (2) 成功率(Success Rate, SR):指智能体最终位置足够接近目标位置(即在预设距离范围内)的比例; (3) 加权路径长度成功率(Success Rate Weighted Path Length, SPL):通过对成功率按轨迹长度进行归一化,综合平衡了到达正确目标的成功率与路径效率。
此外,还有一些指标用于衡量智能体对指令的忠实程度以及预测轨迹与真实轨迹之间的一致性,例如: (4) 基于路径长度加权的覆盖率得分(Coverage Weighted by Length Score, CLS)(Jain 等人,2019),用于衡量智能体的轨迹与参考路径的接近程度。该指标综合考虑了两个关键因素:对参考路径的覆盖程度,以及智能体导航的效率(通过路径长度得分体现); (5) 归一化动态时间规整(Normalized Dynamic Time Warping, nDTW)(Ilharco 等人,2019),用于惩罚智能体轨迹偏离真实轨迹的程度; (6) 考虑成功率的归一化动态时间规整(Success weighted Dynamic Time Warping, sDTW)(Ilharco 等人,2019),在惩罚轨迹偏离真实轨迹的同时,也考虑了导航成功率。
基础模型
基础模型(Foundation Models)在大规模数据集上进行训练,展现出对广泛下游任务的强大泛化能力。 仅基于文本的基础模型(text-only foundation models),如预训练语言模型 BERT(Kenton & Toutanova, 2019)和 GPT-3(Brown et al., 2020),通过在文本生成、翻译和理解等任务上设立新的基准,彻底革新了自然语言处理(NLP)领域。
在这些模型成功的基础上,视觉语言(Vision-Language, VL)基础模型——例如 LXMERT(Tan & Bansal, 2019)、CLIP(Radford et al., 2021)以及 GPT-4(Achiam et al., 2023)——将这一范式扩展到了多模态学习领域。它们同时整合视觉与文本信息,在多种视觉语言任务中表现出显著影响力(Li et al., 2019a; Ramesh et al., 2021; Alayrac et al., 2022; Hong et al., 2021; Zhang et al., 2025; Cheng et al., 2024; Kamali & Kordjamshidi, 2023)。
若读者希望进一步了解基础模型及其应用,推荐参考现有综述性论文,如 Bommasani et al. (2021)、Du et al. (2022) 和 Zhou et al. (2023)。
世界模型:学习和表示视觉环境
世界模型可以帮助VLN理解他们周围的环境,预测他们的行为将会如何改变世界的状态,同时将感知和动作与语言指令对齐。在现有的关于学习世界模型的工作中,有两大挑战:在当前序列(episode)下,将观测的视觉历史进行编码并作为记忆存储;在没见过的环境下表现出强泛化性。
历史和记忆
与其他视觉语言任务(如视觉问答 Visual Question Answering (VQA)(Antol 等, 2015)和视觉蕴含 Visual Entailment(Xie 等, 2019))不同,视觉语言导航(VLN)智能体需要将过去动作与观测的历史信息融入当前步骤的输入中,以决定下一步行动,而不仅仅依赖于单步中的图像和文本输入。
在基础模型被引入 VLN 任务之前,LSTM 的隐藏状态通常作为一种隐式记忆机制,用于辅助智能体在导航过程中的决策。随后研究者们提出了多种改进方法,如设计不同的注意力机制(Tan 等, 2019;Wang 等, 2019)或辅助任务(Ma 等, 2019;Zhu 等, 2020),以提升编码的历史信息与语言指令之间的对齐效果。
历史编码(History Encoding)
为了在基础模型中编码导航历史,研究者提出了多种方法。 一种常见做法是基于多模态 Transformer,以编码后的指令与导航历史为输入进行决策。这类模型通常初始化自在领域内指令-轨迹数据上预训练的模型(如 Prevalent(Hao 等, 2020))。
部分方法通过递归更新的状态 token来编码导航历史。例如:
- Hong 等(2021)提出使用上一步的单个
[CLS]token 来表示历史信息; - Lin 等(2022a)则引入了一种可变长度记忆框架,在记忆库中存储多个先前步骤的动作激活,用于历史编码。
尽管这些方法效果良好,但由于需要逐步更新 token,导致在任意导航步骤高效检索历史信息变得困难,从而限制了其在预训练阶段的可扩展性。
另一类方法直接将导航历史作为一个序列输入到多模态 Transformer 中:
- Pashevich 等(2021)对轨迹中每一步的单视角图像进行编码;
- Chen 等(2021b)进一步提出了全景编码器(panorama encoder),用于在每个时间步编码全景视觉观测,随后再通过历史编码器(history encoder)处理所有过往观测。 这种层次化结构在设计上将单个全景的空间关系与不同时间步之间的时序动态分开建模。同时,它摆脱了对逐步更新状态 token 的依赖,使得在大规模指令-路径对上的高效预训练成为可能。
后续研究中,部分工作用图像均值池化(mean pooling)(Kamath 等, 2023)或前视图编码(front-view encoding)(Qiao 等, 2022)替代全景编码器,依然保持了良好的导航性能。
随着基于大语言模型(LLM)的导航智能体的出现,一些研究(Zhou 等, 2024b)开始尝试将视觉环境转换为文本描述,即通过语言来“解释世界”。导航历史则被编码为这些图像描述的序列,并结合相对空间信息(如朝向、俯仰角、距离等)。 例如,HELPER(Sarch 等, 2023)设计了一种由语言-程序对(language-program pairs)组成的外部记忆结构,通过检索增强的 LLM 提示(retrieval-augmented prompting)将自然语言的人机对话解析为行动程序。
基于图的历史表示(Graph-based History)
另一类研究通过引入图结构信息增强导航历史的建模。 例如,一些方法使用结构化 Transformer 编码器(structured Transformer encoder)来捕捉环境中的几何线索(Chen 等, 2022c;Deng 等, 2020;Wang 等, 2023b;Zhou & Mu, 2023;Su 等, 2023;Zheng 等, 2024b;Wang 等, 2021;Chen 等, 2021a;Zhu 等, 2021a)。
除了用于编码的拓扑图之外,许多研究还引入了不同类型的地图信息来建模导航过程中的观测历史,例如:
- 栅格地图(grid map)(Wang 等, 2023g;Liu 等, 2023a)
- 语义地图(semantic map)(Hong 等, 2023a;Huang 等, 2023a;Georgakis 等, 2022;Anderson 等, 2019;Chen 等, 2022a;Irshad 等, 2022)
- 局部度量地图(local metric map)(An 等, 2023)
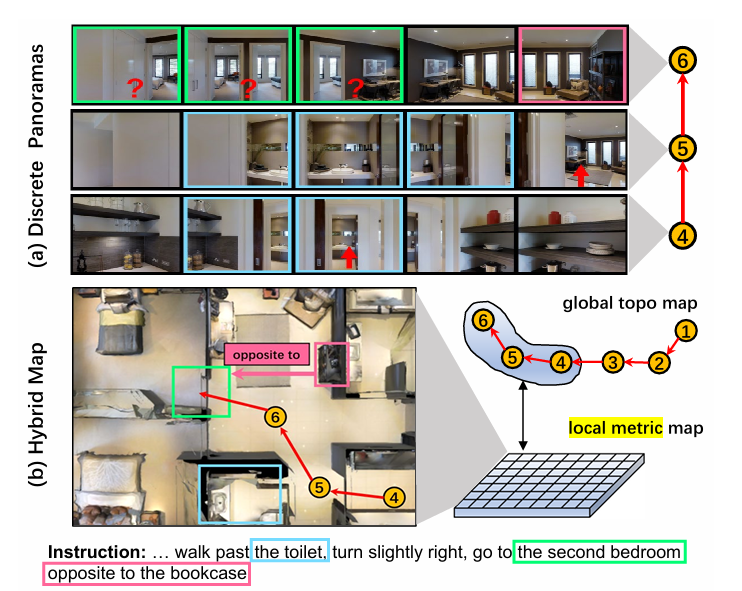
所谓局部度量地图是说,首先预定义一个全局拓扑图,然后将当前位置的结点和周围相邻的结点提取出来作为拓扑子图,这些结点可以分成三类:已访问结点、当前结点、未访问节点,对于每一个结点,使用ViT将全景图片表示成特征图,多个视角平均之后作为该结点的表示。(已访问节点和当前节点使用所有视角的平均,而未访问节点使用包含目标的图片的特征的平均。)
- 局部邻域地图(local neighborhood map)(Gopinathan 等, 2023)
语义地图可看作是在栅格地图的基础上标出了像素的类别信息,即带有语义标签的栅格地图,
近期,随着 LLM 导航智能体的快速发展,研究者在基于地图的记忆构建方面提出了新的思路。例如:
- Chen 等(2024a)提出了一种地图引导的 GPT 智能体,使用语言形式化的地图(linguistically-formed map)来存储和管理拓扑图信息;
- MC-GPT(Zhan 等, 2024b)则引入了一种拓扑地图结构的记忆机制,用于记录视角点、物体及其空间关系信息。
跨环境泛化能力(Generalization across Environments)
在视觉语言导航(VLN)任务中,一个主要挑战是如何在有限的可用环境中学习,并泛化到新的、未见过的环境。许多研究表明,从语义分割特征中学习(Zhang 等, 2021a)、在训练过程中对环境信息进行随机丢弃(dropout)(Tan 等, 2019)、以及最大化来自不同环境但语义对齐的图像对之间的相似性(Li 等, 2022a),都能提升智能体在未见环境中的泛化性能。这些发现表明,要避免模型过拟合训练环境,需要从大规模环境数据中进行学习。接下来,我们将讨论现有研究是如何收集新的环境数据并将其用于训练的。
预训练视觉表征(Pre-trained Visual Representations)
大多数研究使用 在 ImageNet 上预训练的 ResNet 来提取视觉特征(Anderson 等, 2018;Tan 等, 2019)。 Shen 等(2022)将 ResNet 替换为 CLIP 的视觉编码器(Radford 等, 2021),该模型通过图像-文本对的对比学习进行预训练,能自然地更好地对齐图像与导航指令,从而提升 VLN 的性能。 Wang 等(2022b)进一步研究了将从视频数据中学到的视觉表征迁移到 VLN 任务中,结果表明,从视频中学习到的时间信息对于导航至关重要。
环境增强(Environment Augmentation)
另一条重要的研究方向是通过自动生成的合成数据来增强导航环境。 例如:
-
EnvEdit(Li 等, 2022b)、EnvMix(Liu 等, 2021)、KED(Zhu 等, 2023)和 FDA(He 等, 2024a)基于 Matterport3D 环境生成合成数据, 具体做法包括:
- 将来自不同环境的房间混合;
- 改变环境的外观与风格;
- 在环境中插值高频特征。
此外,Pathdreamer(Koh 等, 2021)和 SE3DS(Koh 等, 2023)进一步研究了如何基于当前观测合成未来视图的环境,并将这些合成视图作为VLN 训练的增强数据使用。
随着基础模型(foundation models)的发展,从收集环境中学习的范式也发生了变化。 在基础模型预训练盛行之前,大多数工作都是直接用自动收集的新环境对训练环境进行增强,并微调基于 LSTM 的 VLN 智能体(Li 等, 2022b;Liu 等, 2021;Koh 等, 2021;2023;Zhu 等, 2023)。
然而,随着预训练在基础模型中的重要性被广泛验证,在 VLN 领域中,在预训练阶段利用收集到的环境进行学习也成为了标准做法(Li & Bansal, 2024;Kamath 等, 2023;Chen 等, 2022b;Wang 等, 2023h;Lin 等, 2023b;Guhur 等, 2021a;He 等, 2024a)。
使用增强的领域内(in-domain)数据进行大规模预训练,已成为缩小智能体与人类性能差距的关键。 研究表明,在领域内预训练的多模态 Transformer 比直接从视觉语言模型(VLMs)如 Oscar(Li 等, 2020)和 LXMERT 初始化的多模态 Transformer 更为有效。
当然可以,下面是你提供的这一大段内容的完整中文翻译,我在保持学术表达准确性的同时,使句子自然流畅、易于理解:
人类模型:理解并与人类交流
除了学习和建模世界之外,VLN(视觉语言导航)智能体还需要一个“人类模型”,以便在不同情境下理解人类提供的自然语言指令,从而完成导航任务。该方向面临两个主要挑战: 一是解决指令歧义问题(resolving ambiguity); 二是提升在不同视觉环境中对具身指令(grounded instructions)的泛化能力。
含糊指令(Ambiguous Instructions)
含糊指令主要出现在单轮导航场景中,此时智能体仅根据最初的指令进行导航,而无法与人类进行后续交互以澄清模糊之处。这样的指令缺乏灵活性,无法训练智能体去适应动态环境中的语言理解与视觉感知。 例如,指令中可能包含当前视角下不可见的地标,或多个视角中都可见但难以区分的地标(Zhang & Kordjamshidi, 2023)。
在基础模型应用到 VLN 之前,这一问题几乎未被充分解决。虽然 LEO (Xia et al., 2020) 尝试汇聚多个从不同视角描述同一路径的指令,但仍依赖于人工标注的指令。相比之下,基础模型具备的全面感知上下文与常识知识(perceptual context and commonsense knowledge)使智能体能够利用外部知识来解释含糊指令,甚至向其他人类模型寻求帮助。
感知上下文与常识知识
大规模跨模态预训练模型(如 CLIP)能够对齐视觉语义与文本语义,使 VLN 智能体能基于当前感知到的视觉对象及其状态来消除歧义,尤其是在单轮导航情境下。
例如:
- VLN-Trans (Zhang & Kordjamshidi, 2023) 使用 CLIP 提取可见且具辨识度的目标对象,构建易于理解的子指令(sub-instruction),并预训练一个“翻译器(Translator)”将原本含糊的指令转换为清晰的子指令表示。
- LANA+ (Wang et al., 2023f) 利用 CLIP 从全景观测中查询地标的语义标签列表,并选择检索得分最高的文本线索作为显著地标的语义表示。
- KERM (Li et al., 2023a) 提出了一种知识增强推理模型,用于检索由语言描述的导航视图事实。
- NavHint (Zhang et al., 2024b) 构建了一个提示(hint)数据集,提供详细的视觉描述,帮助 VLN 智能体建立对视觉环境的整体理解,而不仅仅聚焦于指令中提到的物体。
另一方面,大语言模型(LLMs)的常识推理能力也可用于澄清或纠正指令中的模糊地标,并将复杂指令拆解为可执行的步骤。 例如:
- Lin et al. (2024b) 利用 LLM 提供开放世界中地标共现的常识,并据此结合 CLIP 进行地标发现。
- SayCan (Ahn et al., 2022) 将指令拆分为一个带有优先级的可执行动作列表,并结合可供性函数(affordance function)为当前场景中出现的物体赋予更高权重。
信息寻求(Information Seeking)
除了依靠视觉感知和情境信息消除歧义,另一种更直接的方式是向交流伙伴——即提供指令的人类——寻求帮助(Nguyen & Daumé III, 2019;Paul et al., 2022)。
这类研究主要面临三大挑战:
- 决定何时请求帮助(Chi et al., 2020);
- 生成提问信息的问题,例如下一步行动、物体位置或方向(Roman et al., 2020;Singh et al., 2022);
- 设计一个可提供查询信息的“神谕(oracle)”,该 oracle 可以是真实的人类(Singh et al., 2022)、基于规则与模板的系统(Gao et al., 2022),或神经模型(Nguyen & Daumé III, 2019)。
在这一框架下,大语言模型(LLMs)和视觉语言模型(VLMs)有潜力扮演两种角色:
- 作为信息寻求模型(提问方);
- 或作为人类助手的代理(信息提供方)。
已有初步研究探索使用 LLM 作为信息寻求模型,决定何时提问以及提问内容。 实现方法包括:
- 一致性预测(Conformal Prediction, CP)(Ren et al., 2023);
- 上下文学习(In-Context Learning, ICL)(Chen et al., 2023c)。
在后一种情况下,基础模型扮演“帮助者(helper)”的角色,拥有任务执行者无法访问的先验知识,如目标位置或环境地图。
近期工作:
- VLN-Copilot (Qiao et al., 2024) 使智能体在遇到困惑时能够主动寻求帮助,其中 LLM 充当副驾驶(copilot)协助导航。
- Fan et al. (2023b) 展示了 GPT-3 能逐步分解训练数据中的真实响应,从而辅助训练一个基于预训练视频语言模型 SwinBert (Lin et al., 2022b) 的 oracle 模型。
- 他们还表明,大型视觉语言模型(如 mPLUG-Owl (Ye et al., 2023))可直接作为强大的零样本 oracle 使用。
- 此外,还出现了自驱动通信智能体(self-motivated communication agents)(Zhu et al., 2021c),通过学习 oracle 给出正面回答的置信度,实现一种自问自答(self-Q&A)机制,从而在推理阶段移除 oracle。
具身指令的泛化(Generalization of Grounded Instructions)
导航数据规模和多样性的限制是影响 VLN 智能体理解多样化语言表达并有效执行指令的重要因素,尤其是在未见环境(unseen environments)中。
尽管语言风格本身在已见与未见环境中具有良好的迁移性(Zhang et al., 2021a),但如何在有限训练指令下将语言与未见视觉环境进行对齐(grounding)仍是困难问题。 基础模型通过预训练表征与指令生成(data augmentation)两种途径缓解了这一问题。
预训练文本表征(Pre-trained Text Representations)
在基础模型出现之前,许多工作使用 LSTM 等文本编码器来表示语言指令(Anderson et al., 2018;Tan et al., 2019)。 基础模型通过预训练表征显著提升了 VLN 智能体的语言泛化能力。
例如:
- PRESS (Li et al., 2019b) 微调预训练语言模型 BERT (Kenton & Toutanova, 2019),获得对未见指令更具泛化性的文本表示;
- 多模态 Transformer(Tan & Bansal, 2019;Lu et al., 2019)推动了 VLN-BERT (Majumdar et al., 2020) 与 PREVALENT (Hao et al., 2020) 等模型的发展,通过在大规模图文配对数据上预训练来获得通用视觉-语言表征;
- Airbert (Guhur et al., 2021b) 采用 ViLBERT 架构,在网络收集的图像-描述对上训练文本表示;
- CLEAR (Li et al., 2022a) 学习跨语言的语言表示,捕获指令背后的视觉概念;
- ProbES (Liang et al., 2022) 通过采样轨迹自我探索环境,并利用检测到的动作与物体短语填充模板自动生成指令,同时采用提示学习(prompt-based learning)加速语言嵌入的适配;
- NavGPT-2 (Zhou et al., 2025) 探索利用预训练视觉语言模型(如 InstructBLIP (Dai et al., 2024) + Flan-T5 (Chung et al., 2024) 或 Vicuna (Zheng et al., 2023))的表征来增强导航策略学习与推理。
指令合成(Instruction Synthesis)
另一种提升智能体泛化能力的方法是合成更多指令。 早期研究采用 Speaker-Follower 框架(Fried et al., 2018;Tan et al., 2019;Kurita & Cho, 2020;Guhur et al., 2021a), 即利用人工标注的“指令-轨迹”对训练一个离线说话者(Speaker,指令生成器),然后根据给定路径的全景序列生成新指令。
然而,Zhao et al. (2021) 发现这些自动生成的指令质量较低,在人类导航评估中表现不佳。 Marky (Wang et al., 2022a;Kamath et al., 2023) 通过多模态扩展的多语言 T5 模型(Xue et al., 2020),结合文本与视觉地标对齐,显著提升了生成质量,在未见环境中的 R2R 路径上达到了接近人类水平。 PASTS (Wang et al., 2023c) 提出一个时空进度感知 Transformer 说话者,更好地利用多视角视觉与动作特征序列; SAS (Gopinathan et al., 2024) 结合环境的语义与结构线索生成包含丰富空间信息的指令; SRDF (Wang et al., 2024c) 通过迭代自训练构建了强大的指令生成器。
此外,一些最新研究(Liang et al., 2022;Lin et al., 2023b;Zhang & Kordjamshidi, 2023;Wang et al., 2023e;Magassouba et al., 2021)在导航过程中动态生成指令。 例如:LANA (Wang et al., 2023e) 引入一种具语言能力的导航智能体,能够在执行导航指令的同时提供路线描述。
| 挑战类型 | 传统方法 | 基础模型方法 | 代表模型 |
|---|---|---|---|
| 含糊指令理解 | 手工标注 + 单模态特征 | CLIP / LLM 融合视觉语义与常识 | VLN-Trans, LANA+, KERM |
| 主动求助 | 规则式对话 | LLM 生成问答 + 自问自答机制 | VLN-Copilot, GPT-3 Oracle |
| 语言泛化 | LSTM 编码 | BERT/VLM 预训练表示 | PRESS, VLN-BERT |
| 指令生成 | Speaker-Follower 离线生成 | 多模态大模型生成或在线生成 | Marky, LANA, PASTS |
当然,以下是该段落的完整中文翻译,我在翻译时尽量保持了学术原文的严谨性和逻辑结构:
VLN 智能体:学习具身推理与规划能力的智能体
尽管“世界模型”和“人类模型”赋予了视觉与语言理解能力,但 VLN 智能体还需要发展具身推理与规划能力(embodied reasoning and planning capabilities),以支持其决策过程。从这一视角出发,我们讨论两个主要挑战:定位与推理(grounding and reasoning)以及规划(planning),并进一步探讨直接将基础模型(foundation models)作为 VLN 智能体骨干结构的方法。
定位与推理(Grounding and Reasoning)
与其他视觉语言任务(如视觉问答 VQA、图像描述 Image Captioning)主要关注图像与文本之间的静态对齐不同,VLN 智能体需要基于自身的动作,对指令与环境中的时空动态进行推理。 具体来说,智能体应当考虑之前的动作,识别当前需要执行的子指令部分,并将文本语义与视觉环境进行对应(grounding),以据此执行相应的动作。
早期方法主要依赖于显式的语义建模或辅助任务设计来获取这种能力。然而,随着基础模型的出现,通过预训练特定任务获得这种能力已成为主流方法。
显式语义定位(Explicit Semantic Grounding)
早期的研究通过显式的语义建模来增强智能体在视觉与语言模态中的定位能力,包括:
- 对运动与地标的建模(Hong 等, 2020b;He 等, 2021;Hong 等, 2020a;Zhang 等, 2021b;Qi 等, 2020a);
- 利用指令中的句法信息(Li 等, 2021);
- 建模空间关系(Zhang & Kordjamshidi, 2022b;An 等, 2021)。
只有极少数工作(Lin 等, 2023a;Zhan 等, 2024a;Wang 等, 2023b)在基础模型背景下探索显式定位。 例如,Lin 等(2023a)提出了动作原子概念学习(actional atomic-concept learning),并将地图视觉观测映射为多模态对齐特征。
基础模型的预训练(Pre-training VLN Foundation Models)
除了显式语义建模外,早期研究还通过辅助推理任务(auxiliary reasoning tasks)来提升智能体的定位能力(Ma 等, 2019;Wu 等, 2021;Zhu 等, 2020;Raychaudhuri 等, 2021;Dou & Peng, 2022;Kim 等, 2021)。 但在基于基础模型的 VLN 智能体中,这类方法较少使用,因为其预训练阶段已经在导航前提供了对时空语义的通用理解。
为增强智能体的定位能力,研究者设计了多种特定的预训练任务,例如:
- Lin 等(2021)引入专门针对场景与对象定位的预训练任务;
- LOViS(Zhang & Kordjamshidi, 2022a)提出了两个任务,分别强化方向信息与视觉信息;
- HOP(Qiao 等, 2022;2023a)引入历史与顺序感知预训练范式(history-and-order aware pre-training),强调历史轨迹信息;
- Li & Bansal(2023)认为让智能体具备预测未来视图语义的能力有助于长路径导航;
- Dou 等(2023)设计了掩码路径建模(masked path modeling)目标,通过重建随机掩码路径来学习轨迹结构;
- Cui 等(2023)提出实体感知预训练(entity-aware pre-training),通过预测与文本对齐的锚定实体来增强定位。
规划(Planning)
动态规划能力使 VLN 智能体能够适应环境变化并实时优化导航策略。 除了利用全局图信息提升局部动作空间的图规划方法外,基础模型,尤其是大语言模型(LLMs)的兴起,也促使 LLM 驱动的规划器进入 VLN 领域。这些规划器借助 LLM 的常识知识与强大推理能力,生成动态计划以改进决策。
基于图的规划器(Graph-based Planner)
近期研究强调通过全局图信息提升导航规划能力。 例如:
- Wang 等(2021);Chen 等(2022c);Deng 等(2020);Zheng 等(2024b)通过利用访问节点的全局图前沿(graph frontiers)来增强局部动作空间;
- Gao 等(2023)提出分层规划,结合高层区域选择与低层节点选择;
- Liu 等(2023a)将全局与局部动作空间扩展至栅格级动作,提高动作预测精度;
- 在连续环境中,Krantz 等(2021);Hong 等(2022);Anderson 等(2021)采用分层规划方法,从预测的局部可通行图中选择局部航点(waypoint)而非低级控制;
- CM2(Georgakis 等, 2022)通过在局部地图中锚定指令实现轨迹规划;
- An 等(2023, 2024);Wang 等(2022c, 2023g);Chang 等(2024)构建全局拓扑图或栅格地图以进行基于地图的全局规划;
- Wang 等(2023a, 2024a)则使用视频预测或神经辐射场模型预测多个未来航点,评估长期效果并选择最优行动。
基于 LLM 的规划器(LLM-based Planner)
同时,一些研究利用 LLM 的常识知识生成基于文本的规划(Huang 等, 2022;2023b)。
- LLM-Planner(Song 等, 2023)生成由子目标组成的详细计划,并在检测到新对象时动态调整计划;
- Mic(Qiao 等, 2023b)与 A2Nav(Chen 等, 2023b)将导航任务分解为细粒度文本指令,Mic 生成静态与动态视角下的逐步计划,而 A2Nav 使用 GPT-3 将指令解析为可执行子任务;
- ThinkBot(Lu 等, 2023)采用“思维链(Chain-of-Thought)”推理生成缺失的交互动作;
- VL-Map(Huang 等, 2023a)遵循 Code-as-Policy(Liang 等, 2023) 框架,将导航指令转化为代码形式的函数序列,并利用动态构建的可查询地图执行目标;
- SayNav(Rajvanshi 等, 2024)基于探索环境的三维场景图,为 LLM 生成可行且上下文合理的高层计划。
基础模型作为 VLN 智能体(Foundation Models as VLN Agents)
随着基础模型的出现,VLN 智能体的架构经历了重大变革。 在最初由 Anderson 等(2018)提出的设计中,VLN 智能体被构建为 Seq2Seq 框架,利用 LSTM 与注意力机制来建模视觉与语言的交互。随着基础模型的兴起,智能体的后端从 LSTM 逐渐过渡到 Transformer,再到大规模预训练系统。
视觉语言模型(VLMs)作为智能体
主流方法将单流视觉语言模型(single-stream VLMs)作为核心结构(Hong 等, 2021;Qi 等, 2021;Moudgil 等, 2021;Zhao 等, 2022)。 这些模型在每个时间步同时处理语言、视觉与历史 token,并通过自注意机制捕捉跨模态关联,以此推断动作概率。
在零样本导航(zero-shot VLN)中:
- CLIP-NAV(Dorbala 等, 2022)利用 CLIP 获取目标对象的自然语言指代表达,并据此进行序列化导航决策。
VLN-CE 智能体(Krantz 等, 2020)与早期的 VLN-DE(Anderson 等, 2018)主要区别在于动作空间: VLN-CE 在连续环境中执行低级控制,而 VLN-DE 在图环境中选择视角节点。
早期方法(Krantz 等, 2020;Raychaudhuri 等, 2021)使用 LSTM 预测低级动作,但随着 航点预测器(waypoint predictor) 的引入,这种方法得以从 DE 迁移至 CE(Krantz 等, 2021;Hong 等, 2022;An 等, 2022;Zhang & Kordjamshidi, 2024)。 航点检测过程通常基于视觉观测(如全景 RGB-D 图像),预测当前视角下的可通行候选航点,再从中选择一个作为目标位置。
大语言模型(LLMs)作为智能体
由于 LLM 拥有强大的推理能力与语义抽象能力,并能在未知大规模环境中实现良好的泛化,近期研究开始直接将 LLM 用作智能体以完成导航任务。
通常做法是:
- 将视觉观测转换为文本描述;
- 与导航指令一起输入 LLM;
- 由 LLM 输出下一步动作预测。
典型研究包括:
- NavGPT(Zhou 等, 2024a)与 MapGPT(Chen 等, 2024a),二者实现了零样本导航;
- DiscussNav(Long 等, 2024b)提出多专家系统(multi-expert system),由若干领域特定 VLN 专家协作完成导航任务,包括指令分析专家、视觉感知专家、完成度估计专家与决策测试专家。 该系统通过任务分解减轻单一模型负担,提升鲁棒性、透明度与整体性能。
其他工作包括:
- MC-GPT(Zhan 等, 2024b)利用记忆拓扑图与人类导航示例丰富策略;
- InstructNav(Long 等, 2024a)将导航任务拆分为子任务并结合多源价值地图;
- 一些研究(Zheng 等, 2024a;Zhang 等, 2024a;Pan 等, 2024)对 LLM 进行微调以更有效地适应具身导航;
- NavCoT(Lin 等, 2024a)引入思维链(Chain-of-Thought, CoT)推理机制,将 LLM 转化为“世界模型+导航推理智能体”,通过未来环境模拟简化决策过程。
这一系列研究表明,经过微调的语言模型在模拟与现实场景中均展现出灵活性与实用潜力,标志着 VLN 从传统范式向具身智能体范式的重要进步。
VLN 智能体学习框架总览
| 方面 | 传统 VLN 智能体(基础模型前) | 基于基础模型的 VLN 智能体(Foundation Models) |
|---|---|---|
| 核心结构 | Seq2Seq 框架 + LSTM + 注意力机制(Anderson et al., 2018) | Transformer / 大规模预训练模型(VLM 或 LLM) |
| 目标能力 | 基于感知的导航与动作预测 | 具身推理(embodied reasoning)与动态规划(planning) |
| 输入模态 | 图像 + 指令文本(静态对齐) | 多模态输入(视觉、语言、历史动作、地图等) |
| 输出 | 离散动作(DE)或低级控制(CE) | 文本化动作推理、连续规划、未来航点预测等 |
当然,以下是该部分的完整中文翻译,保持学术风格和逻辑清晰性:
挑战与未来方向
尽管基础模型(foundation models)为 VLN(视觉语言导航)提供了新的解决方案,但仍存在许多尚未充分研究的局限,同时也出现了新的挑战。本节将从基准任务(benchmarks)、世界模型(world model)、人类模型(human model)、智能体模型(agent model)以及真实机器人部署(real robot deployment)等角度,讨论 VLN 的挑战与未来发展方向。
基准任务:数据与任务的局限性
当前的 VLN 数据集在质量、多样性、偏差以及可扩展性方面仍存在不足。例如,在 R2R 数据集中,指令—轨迹配对往往偏向最短路径,这并不能准确反映现实世界的导航情境。我们讨论 VLN 基准任务的改进趋势与建议如下:
- 统一且真实的任务与平台:
为了在真实世界中评估 VLN,建立稳健的基准和确保可复现性至关重要。现实世界的多样性要求基准能够全面反映导航中的挑战。类似 OVMM(Yenamandra 等, 2023)这样的通用模拟到现实(sim-to-real)评测平台,有助于在仿真与真实环境中实现标准化测试。此外,任务与活动应当具有现实性,并源于人类的实际需求。例如,BEHAVIOR-1K(Li 等, 2024a)在虚拟、交互式、生态化的环境中构建了日常家务活动的基准,以满足任务多样性与真实性的需求。
- 动态环境:
现实世界的环境本质上复杂且动态,存在移动的物体、行人以及光照、天气等变化,这些都会造成意外情况(Ma 等, 2022)。这些因素会扰乱导航系统的视觉感知,使得保持稳定性能变得困难。近期的研究,如 HAZARD(Zhou 等, 2024c)、Habitat 3.0(Puig 等, 2024)和 HA-VLN(Li 等, 2024b),开始考虑动态环境,为未来研究提供了良好的起点。
- 从室内到室外:
VLN 智能体在室外环境(如自动驾驶和无人机导航)中的应用也开始受到关注(Vasudevan 等, 2021;Li 等, 2024c),相应地也出现了多种语言引导的数据集(Sriram 等, 2019;Ma 等, 2022)。早期研究尝试在这些任务中引入大语言模型(LLMs),或通过提示工程(prompt engineering)(Shah 等, 2023;Sha 等, 2023;Wen 等, 2023),或通过微调 LLM 来预测下一个动作或规划未来轨迹(Chen 等, 2024b;Mao 等, 2023)。
为了使通用视觉语言模型(VLMs)适应室外导航领域,研究者利用了真实驾驶视频(Xu 等, 2024a;Yuan 等, 2024)、仿真驾驶数据(Wang 等, 2023d;Shao 等, 2024),或两者结合(Sima 等, 2023;Huang 等, 2024b)进行指令调优(instruction tuning),使模型能够学习预测未来的油门与转向角。除此之外,研究者还在驾驶智能体中引入了额外的推理与规划模块(Huang 等, 2024b;Tian 等, 2024)。更详细的综述可参见(Li 等, 2023b;Cui 等, 2024;Gao 等, 2024;Yan 等, 2024)。
世界模型:从二维到三维
构建有效的世界表征是具身感知、推理与规划的核心研究主题。VLN 本质上是一个三维任务,智能体在三维环境中进行感知。尽管当前研究多采用强大的二维表示,但它们在理解三维空间语言时仍存在不足(Zhang 等, 2024d)。
以往工作提出了多种显式的三维表示方法,包括语义 SLAM 与体积表示(Chaplot 等, 2020;Min 等, 2021;Saha 等, 2022;Blukis 等, 2022;Zhang 等, 2022b;Liu 等, 2024)、深度信息(An 等, 2023)、鸟瞰图表示(如栅格地图)(Wang 等, 2023g;Liu 等, 2023a)以及局部度量地图(An 等, 2023)。
然而,这些方法通常假设封闭的对象集合,难以适应开放词汇(open-vocabulary)场景下的自然语言指令。近期研究尝试通过将 CLIP 提取的多视角图像特征嵌入 3D 体素网格(Jatavallabhula 等, 2023;Chang 等, 2023)或顶视特征图(Huang 等, 2023a;Chen 等, 2023a),以及利用场景图(Rana 等, 2023;Gu 等, 2024)来表示空间关系。
如何将大规模数据中学到的三维表示有效迁移到 VLN 智能体,使其更好地感知三维环境,仍是一个开放问题。近期出现的 3D 基础模型(Hong 等, 2023b;Huang 等, 2024a;Chen 等, 2024d;e),包括 3D 重建模型(Hong 等, 2024)和 3D 多模态表示(Yang 等, 2024;Zhang 等, 2024c;e),有望在这一方向上发挥关键作用。
人类模型:从指令到对话
以往工作主要采用“说话者—听众”(speaker-listener)范式或受限的问答式对话(Thomason 等, 2020;Gao 等, 2022),其中智能体只能请求帮助。近期出现了一系列支持开放式对话指令的新基准(De Vries 等, 2018;Banerjee 等, 2021;Padmakumar 等, 2022;Ma 等, 2022;Fan 等, 2023a),允许智能体在含糊或混乱情境下进行自由交流,包括提问、建议、解释、澄清与协商。
然而,当前方法多依赖基于规则的对话模板来应对这些复杂性(Zhang 等, 2023;Parekh 等, 2023;Gu 等, 2023),即便其中包含基础模型组件。Huang 等(2024b)在视频语言模型上进行对话微调,利用人类对话与仿真导航视频配对数据,在导航过程中展现了更强的对话生成能力。
未来研究应当进一步将基础模型融入具身任务导向对话管理(Ulmer 等, 2024),或探索现有基础模型在任务导向对话中的应用(He 等, 2022)。
智能体模型:将基础模型适配于 VLN
尽管基础模型具备强泛化能力,将其应用于导航任务仍面临挑战。LLM 从根本上缺乏对实际环境的视觉感知能力,并容易产生幻觉(hallucination)。以下是几个关键问题:
-
缺乏具身经验: 由于缺乏真实交互经验,LLM 在任务规划与推理中往往依赖常识知识,而这可能无法满足具体的现实需求(Xiang 等, 2024)。有些方案通过将视觉观测转换为文本描述后输入 LLM(Zheng 等, 2022),但这可能导致视觉语义的损失。相比之下,视觉语言模型(VLM)智能体能够同时感知视觉世界并进行规划(Zhang 等, 2024a),但这些模型大多来自互联网数据,缺乏具身经验(Mu 等, 2024),因此仍需微调以增强决策能力(Zhai 等, 2024)。 近期提出的具身基础模型(Embodied Foundation Models),如 EmbodiedGPT(Mu 等, 2024)、PaLM-E(Driess 等, 2023)与 Octopus(Yang 等, 2025),通过在多具身任务上微调,弥合了视觉、语言与动作之间的差距,显著提升了模型在交互环境中的操作能力。
-
幻觉问题: LLM 和 VLM 可能生成并不存在的对象,造成错误信息(Li 等, 2023c;Chen 等, 2024c)。例如,LLM 在规划任务时可能生成“向前走然后在沙发处左转”这样的指令,即便环境中并无沙发,从而导致错误或无法执行的动作。
-
LLM 在规划与推理中的作用:
一些研究评估了 LLM 的零样本推理与规划能力,特别是在 PlanBench(Valmeekam 等, 2022)与 CogEval(Momennejad 等, 2023)中的表现。这些研究发现,LLM 在生成计划、最优性、鲁棒性与推理等复杂规划任务上仍存在困难,容易出现幻觉或未能理解复杂关系结构。 在 VLN 场景中,动作空间与规划需求相对受限(如固定的室内环境与有限的导航动作集合),这使得 LLM 能够以分步指令的形式提供粗粒度导航指导。此前的研究表明这种方式有效。在 VLN 中,LLM 的作用并非接管整个规划过程,而是辅助提供结构化的指令分解;而感知与运动控制等模块仍是决策的主要依据。因此,LLM 在 VLN 中的规划更像是辅助性的引导,而非唯一的决策来源。
部署:从仿真到真实机器人
仿真环境往往缺乏现实世界的复杂性与多样性,且较低质量的渲染图像进一步加剧了这一差距。首先,感知差距导致性能下降,凸显了对更鲁棒感知系统的需求。Wang 等(2024b)探索了使用语义地图与三维特征场,为单目机器人提供全景感知,从而显著提升性能。
同时,具身差距与数据稀缺仍是瓶颈。近期提出的“机器人瞬移”(robot teleportation)(He 等, 2024b)为基础模型在真实人机交互中的 VLN 数据扩展提供了一种新的可扩展方式。
更广泛的影响
基础模型在推动视觉语言导航领域的发展方面潜力巨大。然而,必须关注其更广泛的伦理、法律与社会影响。由于这些模型是在大规模网络数据上预训练的,它们可能携带固有偏差,从而引发公平性问题,例如对多语言用户的不公。
此外,部分方法涉及持续训练,因此在模型的现实部署(如家用机器人)中,必须重视并防范对用户隐私可能造成的风险。
后记
感觉这篇综述写的一般,全篇的结构是清晰的,但是有些内容阐述得不是很明白,需要读者亲自去阅读相关的文献。把 VLN 分成世界模型、人类模型、智能体模型看似很合理,但是在很多工作中这三个模型其实就是一个 VLM,这就导致相同的内容重复说个几遍,有些冗余,大家都懂的废话也有不少,没有什么读到的见解,浅读一下了解了解 VLN 的各领域工作倒是可以。
本篇内容大多使用 AI 翻译,如有偏差请查阅原文献。
Leave a comment